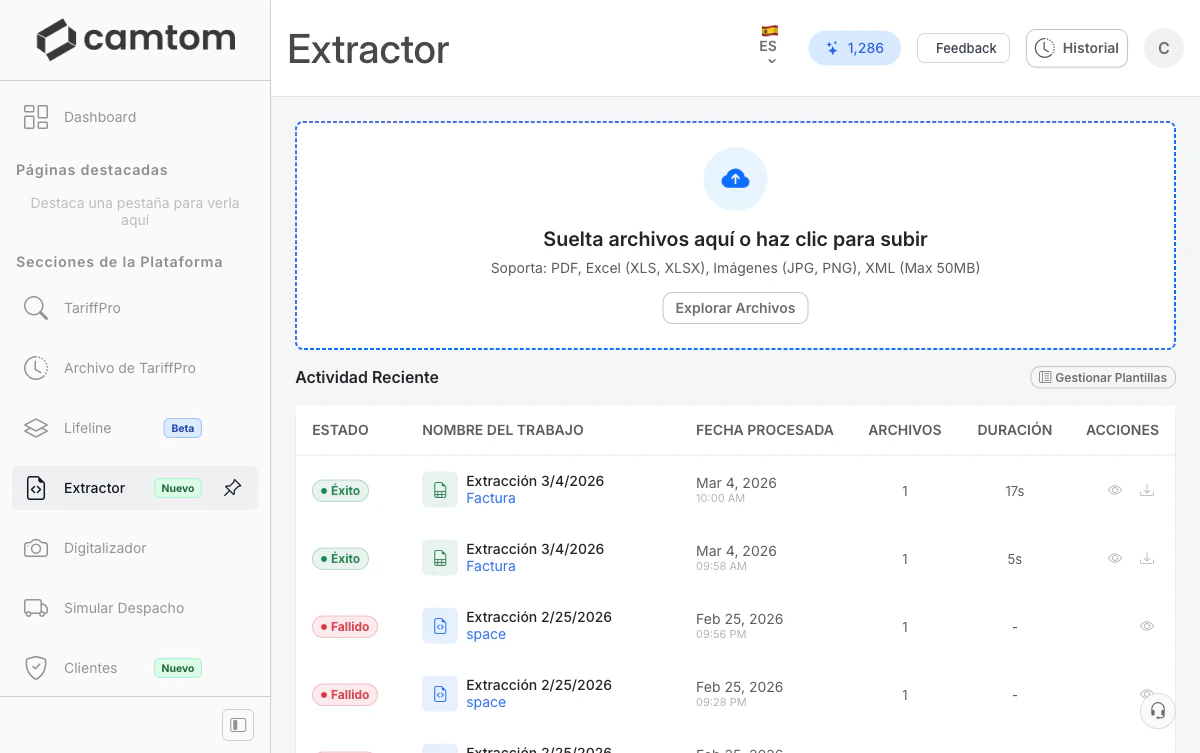
Capacidades principales
Extracción de datos
Extrae campos específicos del documento y los devuelve como datos estructurados en formato JSON, siguiendo el esquema que tú defines.
Esquemas personalizados
Define exactamente qué campos necesitas extraer usando JSON Schema Draft 7. La IA se adapta a tu esquema.
Multi-formato
Procesa PDFs (nativos y escaneados), imágenes (JPEG, PNG, TIFF, BMP, GIF, WebP), Excel (XLSX, XLS, ODS) y XML.
Documentos largos
Procesa documentos de hasta 300 páginas. Para PDFs digitales extensos, activa automáticamente un procesamiento avanzado especializado.
Extracción inteligente
CamtomDocs adapta automáticamente su procesamiento según el tipo y tamaño del documento para obtener los mejores resultados:- Documentos cortos y formatos variados: Para la mayoría de documentos (PDFs cortos, imágenes, Excel, XML), tú proporcionas un JSON Schema Draft 7 que describe los campos que necesitas, y la IA extrae la información correspondiente. Funciona con cualquier tipo de documento y te da control total sobre los campos extraídos.
- PDFs digitales extensos: Para PDFs digitales largos, CamtomDocs activa automáticamente un procesamiento avanzado que analiza el documento sección por sección, con capacidades especializadas para tablas complejas y estructuras que abarcan múltiples páginas. Ideal para documentos extensos con estructura tabular compleja.
Sistema de créditos
CamtomDocs utiliza un sistema de créditos transparente:
Ejemplos de consumo por extracción:
Caso de uso típico
Una agencia aduanal recibe diariamente decenas de facturas comerciales, packing lists y certificados de origen de sus clientes. Con CamtomDocs, el proceso es:1
Recepción del documento
El cliente envía sus documentos por correo o los sube a la plataforma.
2
Definición del esquema
Se proporciona un JSON Schema Draft 7 que describe los campos a extraer (o se usa uno previamente configurado). Si no se envía un schema, el sistema puede inferir uno a partir de la descripción del documento.
3
Extracción automática
CamtomDocs procesa el documento: aplica OCR si es necesario, selecciona el procesamiento más adecuado y extrae los datos según el esquema.
4
Datos listos para operar
La información estructurada en JSON alimenta directamente los flujos de trabajo de la agencia, eliminando la captura manual.
Siguiente paso
¿Cómo funciona?
Conoce el flujo técnico de procesamiento paso a paso.
Documentos soportados
Consulta la lista completa de tipos de documentos y formatos.